In the constantly evolving field of machine learning, a new architecture called Mamba is gaining attention. It not only has an intriguing name but also delivers impressive empirical results. Mamba represents a significant advancement in sequence modeling, a deep learning domain focused on efficiently handling long data sequences.
The Challenges with various other Architectures
The transformer architecture is the core of the GPTs. They use ‘attention’. This means that you can dynamically and selectively look back at each individual elements or hidden states, to retain the context. But this comes at a cost. The challenge with the transformer architecture is that it takes computation/memory of L2 where L is the length of the sequence.
Now, coming to RNNs. RNNs look back at only one time step. That means the current state and the previous hidden state will be used to make predictions. The memory/computation it utilizes will also be of a constant time where It depends on the size of the hidden state and the input. The problem arises with backpropagation. Backpropagation in RNNs often suffers from vanishing or exploding gradients. Vanishing gradients prevent the model from learning long-term dependencies, while exploding gradients cause instability during training. These issues make it challenging to train RNNs effectively on tasks involving long sequences of data.
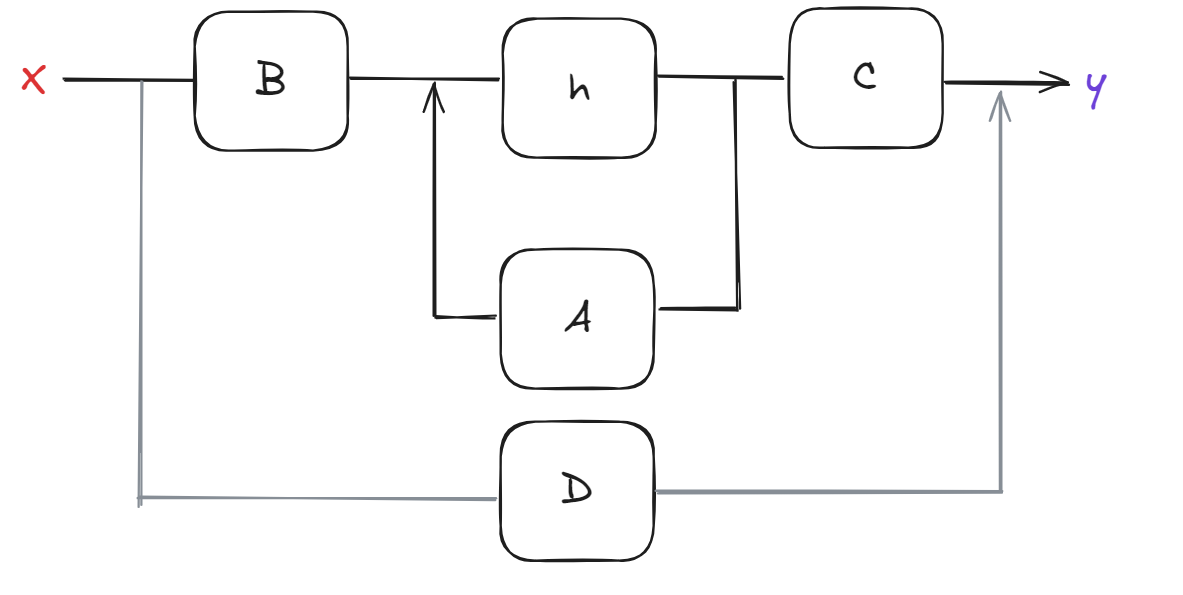
Next comes the Structured State Space Sequence Models (S4) which are essentially RNNs but when they have a sequence of inputs, they can compute all in one go, ZOOM! which is efficient parallel computing that allows for handling long sequences effectively. Let us understand the working of S4. In simple S4, there are two main features:
1. no activation function (σ) in the Transition from ht to ht+1
2. No time dependency. This means that the transition from one time step to another is treated same or as one.
Why Mamba?
Mamba relaxes these properties of S4, but retains the sequence property that is the computation will happen in one go. ZOOM! Unlike LSTM where you have to maintain forward pass one after the other. So during training it would look more like a transformer but during inference it looks like a LSTM.
S4’s are a part of Mamba combined with a 1D convolutions and Up Projections with some sort of gating. It is basically ‘attention’ free which avoid quadratic bottlenecks.
To understand the technical intricacies that goes behind, it is important to first understand the ones of S4.
Understanding the Structured State Space Sequence Models
ℎt = Āℎt-1 + B̅xt
Here, both terms can be thought of as learnable matrices. When we look at it this way then this is just a simple RNN with some linearity.
yt = Cht
So, finally the output is computed as the linear function of the hidden state.
Understanding the output
Lets compute for y3
y3 = C(Āℎ3 + B̅x3)
h1 = Āh0 + B̅x1
h2 = Āh1 + B̅x2
h3 = Āh2 + B̅x3
y3=C Ā2B̅x1 + CĀB̅x2 + CB̅x3
Here CAAB, CAAB… can be considered as a constant learnable (kernel) that can be precomputed, and X1, X2… as their inputs. So, the output will be a dot product of them. Hence to compute the sequence just have to precompute the learnable and take a dot product with the sequence of input. This is how the ZOOM action takes place, which is basically a convolution operation.
Here comes the Mamba
In mamba the Δ, A, B, C will be input dependent. Hence, the ‘ZOOM’ would not be done using convolution which requires the kernel to be a constant (CAAB is now CA1A2B), which is now done using a pre-fix sum (parallel scan). So you precompute all the multiplication combination sums of C,A,B and store them.
Mamba: Revolutionizing Sequence Modeling Beyond Transformers and RNNs